Rozwiązanie OpenText Capture Center (OCC) pozwala na automatyczne pozyskiwanie i interpretację zawartości papierowych dokumentów, skanowanych obrazów, wiadomości email oraz faksów. OCC wykorzystuje najbardziej zaawansowane techniki rozpoznawania i klasyfikacji dokumentów oraz znaków, dokonując zamiany dokumentów na gotową do maszynowego przetwarzania informację.
OPENTEXT CAPTURE CENTER
Technologie
Stosowane są techniki OCR (Optical Character Recognition, rozpoznawanie znaków/tekstów), ICR (Intelligent Character Recognition, rozpoznawanie różnych rodzajów pisma i i ch właściwości) i korzystającego z nich IDR (Intelligent Document Recognition, ekstrakcja i interpretacja treści z dokumentów). Dzięki temu możliwe jest znaczące zredukowanie ręcznego przepisywania danych z dokumentów, przyspieszenie obsługi dokumentów w procesach biznesowych, polepszenie ich jakości i zredukowanie czasochłonności oraz szereg innych korzyści.
Źródła danych i rozpoznawane formaty
Ekstrakcja danych przebiega wieloetapowo:
Pozyskiwanie dokumentów
Stacje skanujące, systemy plików, serwery FTP, serwery email, serwery Microsoft SharePoint). Obsługiwanych jest bardzo wiele formatów źródłowych (np. TIFF, JPG, BMP, GIF, PNG, PCX, PDF, PDF/A, email, …), w wielu językach (w tym język polski) i alfabetach.
Rozpoznawanie dokumentów, obejmuje automatyczną klasyfikację dokumentu, a następnie wykonanie stosownego profilu ekstrakcji danych dla danej klasy dokumentu. Klasa dokumentu określa zestaw pól (metadanych, indeksów), ich lokalizacji w dokumencie oraz sposobu ekstrakcji. Klasyfikacja może odbywać się na podstawie źródła, reguł, kodów (np. barkodów, patch kodów, separatorów), adaptacyjnie (ACT – Automatic Classification Technology – tj. na podstawie wcześniej wyuczonych mechanizmów, np. na podstawie zbioru dokumentów treningowych). Na tym etapie następuje także separacja (i/lub łączenie) dokumentów w dokumenty logiczne. OCC przy ekstrakcji danych z dokumentów posługuje się różnymi metodami, np. określanie typu pola, adaptacyjną klasyfikację (np. automatyczne określenie języka dokumentu na podstawie jego treści), adaptacyjne rozpoznawanie (na podstawie wcześniej wyuczonych zbiorów dokumentów treningowych), porównywanie zidentyfikowanej zawartości pól dokumentu z danymi w zewnętrznych bazach danych oraz silnik reguł biznesowych. Dostępna jest także specyficzna ścieżka przetwarzania dla faktur (np. ekstrakcja nagłówka faktury i jej składników – linii) dla kilkudziesięciu krajów (w tym dla Polski) oraz dla formularzy.
-
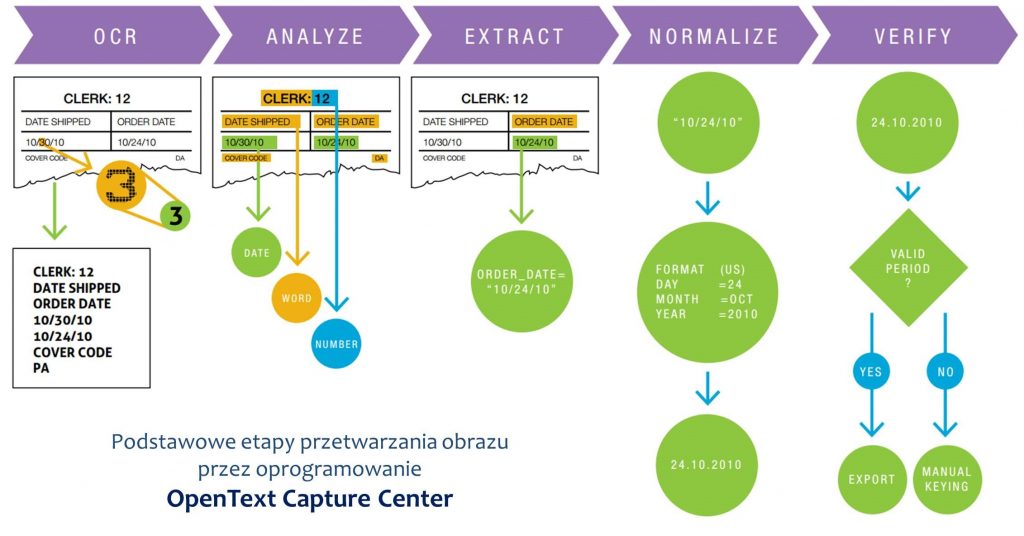
- OpenText Capture Center
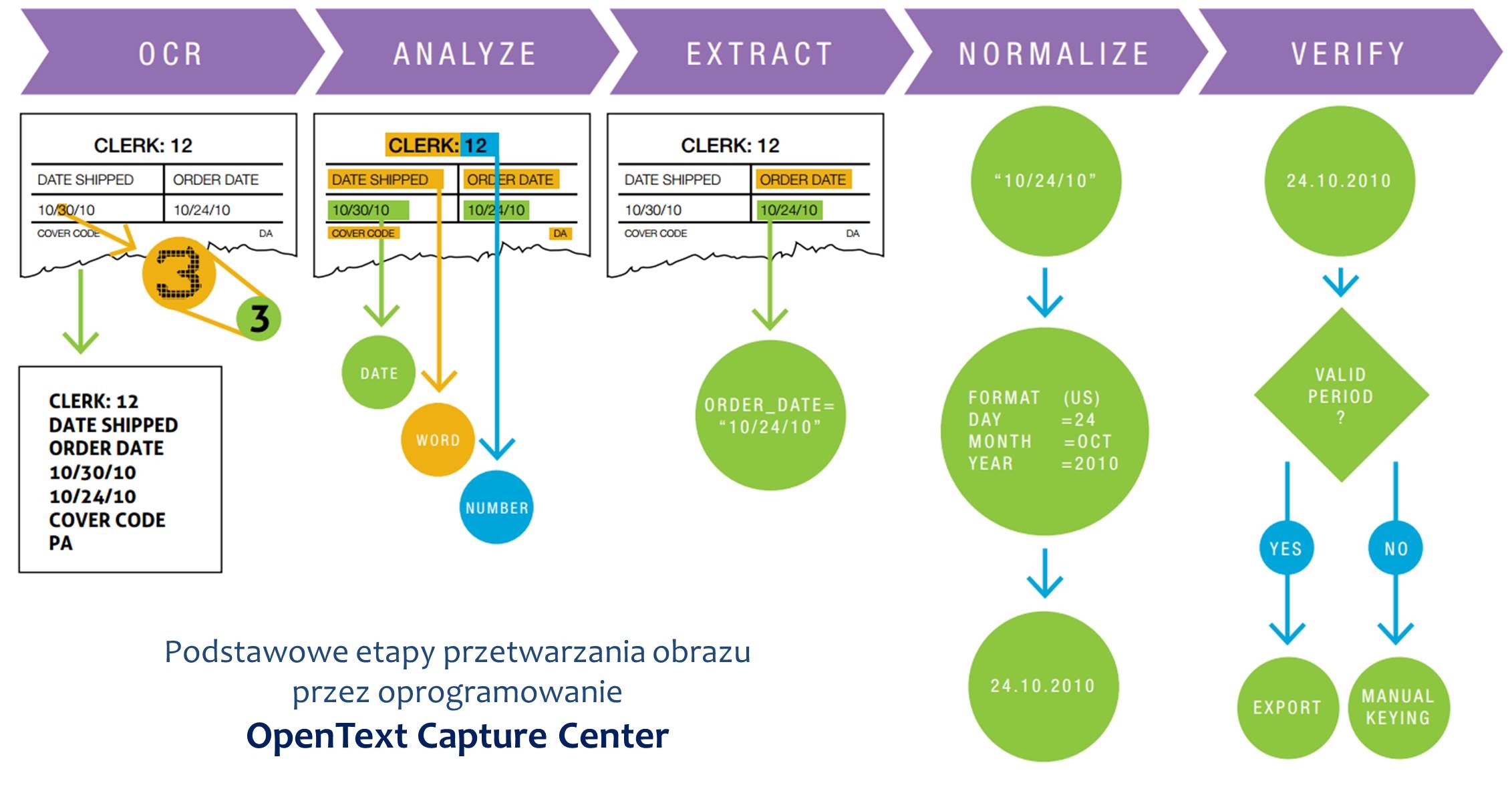
Weryfikacja i korekta odczytu
Walidacja dokumentów – zdecydowana większość dokumentów jest przetwarzana w pełni automatycznie, natomiast czasami mogą pojawić się problemy z poprawną identyfikacją danych (np. w wyniku niskiej jakości źródłowych dokumentów, nietypowych czcionek lub nietypowego układu dokumentu). W przypadku gdy system oznaczy pewność zidentyfikowanych danych jako niewystarczającą, dokument jest kierowany do ręcznej walidacji. Przy użyciu bardzo wygodnej, intuicyjnej aplikacji, operator poprzez wskazywanie stosownych miejsc w dokumencie, może szybko uzupełnić i skorygować dane. Tak uzupełniony dokument jest kierowany do kolejnych kroków przetwarzania.
Pozyskiwanie dokumentów:
Przekazywanie dokumentu do docelowej aplikacji – dokument (tj. jego obraz/skan wraz z rozpoznanymi metadanymi) jest kierowany do docelowej aplikacji (np. folderu w systemie plików, repozytorium dokumentów, systemu archiwizacji czy aplikacji biznesowej, np. SAP). Format wyjściowy jest konfigurowalny (np. TIFF, PNG, PDF, PDF/A, XML, OpenText Content Server, SharePoint). Rozwiązanie jest rozszerzalne, tj. poprzez interfejsy programistyczne (API) istnieje możliwość zintegrowania procesu wprowadzania dokumentów i rozpoznanych z nich danych do dowolnych systemów.
Istnieje możliwość dołączania własnych skryptów do każdego etapu przetwarzania dokumentu (np. przed/po importem, po separacji, po klasyfikacji, po ekstrakcji danych, w sytuacjach błędów, po walidacji, przed/po eksporcie). Na każdym z etapów skrypty mogą manipulować danymi dokumentów (i samego procesu przetwarzania), co pozwala na przykład na walidację pól, których wartość jest określona formułą i które korzystają z innych danych w dokumencie.
Integracja z SAP
OCC ściśle integruje się z systemami SAP, m.in. pozwalając na inicjowanie transakcji, workflow i procesów biznesowych kontrolowanych przez systemy SAP w wyniku pojawienia się dokumentów, transfer danych z dokumentów do SAP, walidację danych rozpoznanych z dokumentów z danymi przechowywanymi w SAP, obsługę kodów paskowych (barkodów), itp. Obsługiwane są wszystkie scenariusze pracy z dokumentami: skanowania z równoczesnym wprowadzaniem do SAP, przypisywania dokumentu do istniejących danych w SAP, nadawania barkodów, ręczne i masowe przetwarzanie dokumentów.